 随遇而安
随遇而安上文中提到,我们请求的resource,会通过ProcessorSlotChain上的slot进行处理,接下来我们将会对核心的slot进行解析。
NodeSelectorSlot
NodeSelectorSlot用于构建调用链路,调用链路是流量控制、权限控制、降级控制的基础架构。
我们通过类注释的例子进行讲解:
ContextUtil.enter("entrance1", "appA");
Entry nodeA = SphU.entry("nodeA");
if (nodeA != null) {
nodeA.exit();
}
ContextUtil.exit();
- 首先,创建了一个名称为entrance1的Context,并制定了调用发起者为appA。
- 其次,通过Sphu上报了了一次请求名称为nodeA的resource。
- 然后,成功获取resource,则释放resource。
- 最后,退出Context。
这段逻辑会在代码中生成如下的调用链路:
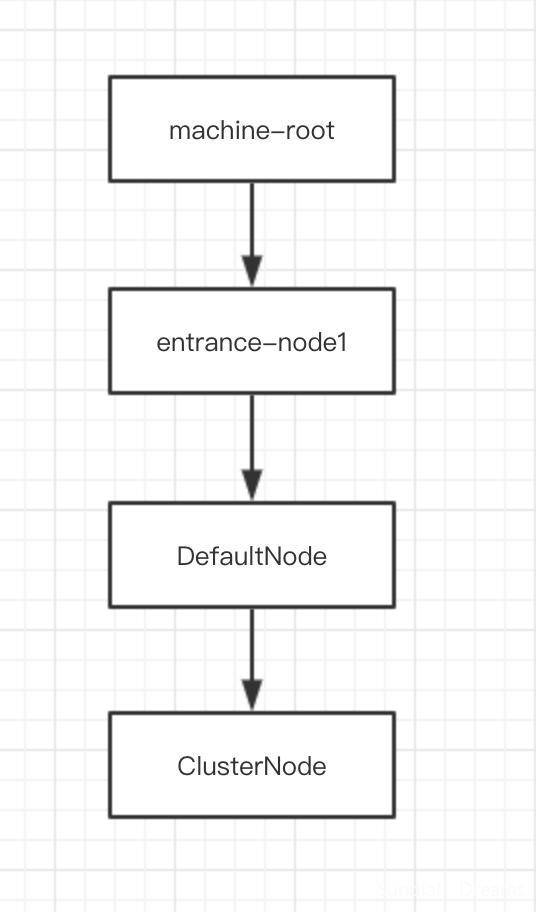
接下来会对这个调用链路进行扩展:
ContextUtil.enter("entrance1", "appA");
Entry nodeA = SphU.entry("nodeA");
if (nodeA != null) {
nodeA.exit();
}
ContextUtil.exit();
ContextUtil.enter("entrance2", "appA");
nodeA = SphU.entry("nodeA");
if (nodeA != null) {
nodeA.exit();
}
ContextUtil.exit();
第一部分代码没有任何变化。
第二部分代码重新创建了一个名称为entrance2的Context,获取的也是名称为nodeA的resource,随后也退出了,那么这段代码生成的调用链路是:
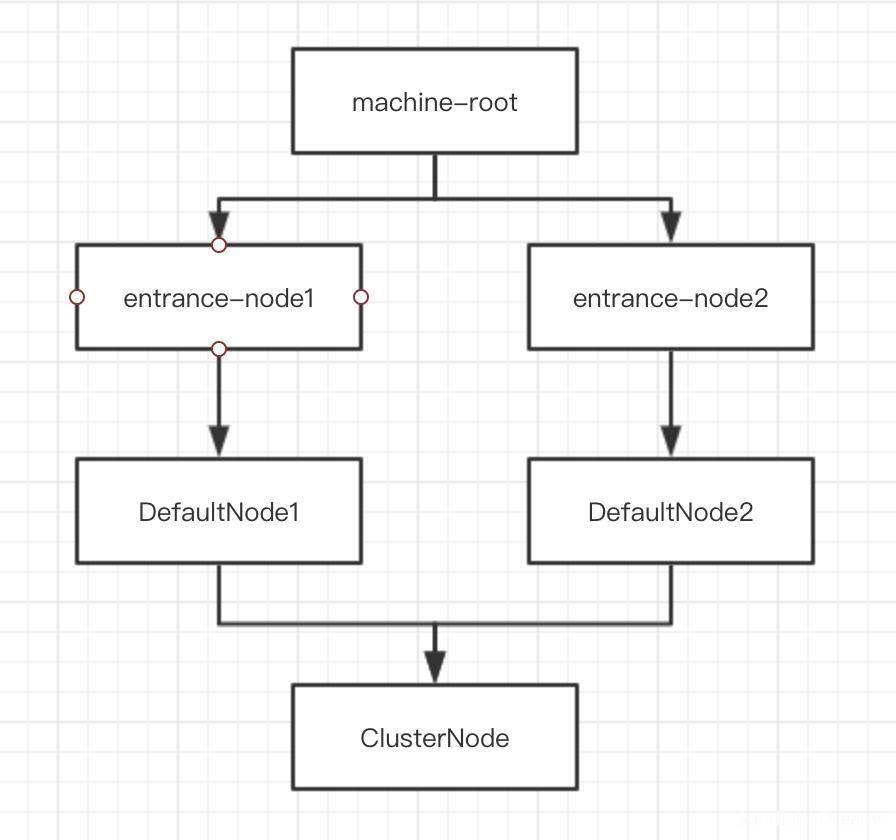
也就是说在请求同一个resource时,可以产生多个entranceNode和DefaultNode,但只会共用同一个ClusterNode。
首先,NodeSelectorSlot私有了一个map集合,用于存储每个调用Context的DefaultNode。
NodoeSelectorSlot#map()
一个思维环绕,Sentinel使用了Context名称代替resource id作为缓存的key,因为Sentinel需要做的是在不同的Context中共享同一个ProcessorSlotChain,所以它采用了缓存Context的方式,使用DefaultNode关联resource。
如果一个resource对应了多个DefaultNode,也就是对应了多个Context,那么如何对请求进行数据统计呢?
每个resource的DefaultNode会共享同一个ClusterNode,在接下来的ClusterBuilderSlot中会给你答案。
NodeSelectorSlot#entry()
我们来看NodeSelectorSlot#entry()方法:
public void entry(Context context, ResourceWrapper resourceWrapper, Object obj, int count, boolean prioritized, Object... args) throws Throwable {
// 获取当前上下文的DefaultNode
DefaultNode node = map.get(context.getName());
if (node == null) {
// 如果不存在当前上下文的数据统计节点,此时就需要为当前上下文创建一个数据统计节点
synchronized (this) {
node = map.get(context.getName());
if (node == null) {
node = new DefaultNode(resourceWrapper, null);
HashMap<String, DefaultNode> cacheMap = new HashMap<String, DefaultNode>(map.size());
cacheMap.putAll(map);
cacheMap.put(context.getName(), node);
map = cacheMap;
}
// 构建调用树
((DefaultNode)context.getLastNode()).addChild(node);
}
}
// 设置处理节点为当前节点
context.setCurNode(node);
fireEntry(context, resourceWrapper, node, count, prioritized, args);
}
- 首先,NodeSelectorSlot缓存了context->defaultNode,我们可以根据context name获取已经调用的信息。
- 其次,会使用双重校验锁的同步方式创建新的context->defaultNode。
- 然后,构建调用链路。
- 最后,将处理节点设置为当前获取到的DefaultNode,进行下一个slot的业务逻辑。
ClusterBuilderSlot
ClusterBuilderSlot持有了resource运行时的所有数据,在链路后端的具体执行操作时,都会从ClusterNode中获取实时数据,这些数据包括响应时间,QPS,线程数量,异常等信息。
ClusterBuilderSlot#clusterNodeMap
ClusterBuilderSlot也私有了一个缓存map,用于存储resource->clusterNode映射关系。
随着应用运行的时间越长,clusterNodeMap就会变得越稳定,并且使用volatile+乐观锁的形式代替ConcurrentHashMap来保证线程安全。
ClusterBuilderSlot#entry()
我们来看调用链路中ClusterBuilderSlot的实现:
@Override
public void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node, int count,
boolean prioritized, Object... args)
throws Throwable {
if (clusterNode == null) {
synchronized (lock) {
// 使用同步的方式创建cluster node
if (clusterNode == null) {
clusterNode = new ClusterNode();
HashMap<ResourceWrapper, ClusterNode> newMap = new HashMap<>(Math.max(clusterNodeMap.size(), 16));
newMap.putAll(clusterNodeMap);
newMap.put(node.getId(), clusterNode);
clusterNodeMap = newMap;
}
}
}
node.setClusterNode(clusterNode);
// 如果上下文中设置了origin信息,需要为此创建一个节点
if (!"".equals(context.getOrigin())) {
Node originNode = node.getClusterNode().getOrCreateOriginNode(context.getOrigin());
context.getCurEntry().setOriginNode(originNode);
}
fireEntry(context, resourceWrapper, node, count, prioritized, args);
}
- 首先,通过同步校验锁的方式初始化ClusterNode。
- 其次,将ClusterNode和当前请求的resource关联的ClusterNode进行关联。
- 然后,如果请求中带有了origin信息,我们也需要为origin创建一个节点,放入到Context中。
- 最后,执行下一个slot的逻辑。
StatisticSlot
StatisticSlot致力于实时数据统计,当进行到StatisticSlot时,Sentinel需要进行ClusterNode的全部数据统计以及DefaultNode针对特定上下文、特定resource的数据统计。
@Override
public void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node, int count,
boolean prioritized, Object... args) throws Throwable {
try {
// 继续进行责任链的后续Slot的处理
fireEntry(context, resourceWrapper, node, count, prioritized, args);
// 后续处理完成之后,回到这里,进行数据统计
node.increaseThreadNum();
node.addPassRequest(count);
if (context.getCurEntry().getOriginNode() != null) {
// 更新origin node的数据
context.getCurEntry().getOriginNode().increaseThreadNum();
context.getCurEntry().getOriginNode().addPassRequest(count);
}
if (resourceWrapper.getType() == EntryType.IN) {
// 更新inbound类型请求的全局数据
Constants.ENTRY_NODE.increaseThreadNum();
Constants.ENTRY_NODE.addPassRequest(count);
}
// 处理注册entry回调任务的通过事件
for (ProcessorSlotEntryCallback<DefaultNode> handler : StatisticSlotCallbackRegistry.getEntryCallbacks()) {
handler.onPass(context, resourceWrapper, node, count, args);
}
} catch (PriorityWaitException ex) {
// 如果抛出因为优先级问题导致的等待问题,更新节点的并发请求数据
node.increaseThreadNum();
if (context.getCurEntry().getOriginNode() != null) {
// 更新origin node的数据
context.getCurEntry().getOriginNode().increaseThreadNum();
}
if (resourceWrapper.getType() == EntryType.IN) {
// 更新inbound类型请求的全局数据
Constants.ENTRY_NODE.increaseThreadNum();
}
// 处理注册entry回调任务的通过事件
for (ProcessorSlotEntryCallback<DefaultNode> handler : StatisticSlotCallbackRegistry.getEntryCallbacks()) {
handler.onPass(context, resourceWrapper, node, count, args);
}
} catch (BlockException e) {
// 阻塞异常
// 设置当前异常
context.getCurEntry().setError(e);
// 更新阻塞数据统计
node.increaseBlockQps(count);
if (context.getCurEntry().getOriginNode() != null) {
context.getCurEntry().getOriginNode().increaseBlockQps(count);
}
if (resourceWrapper.getType() == EntryType.IN) {
// 更新inbound类型请求的全局数据
Constants.ENTRY_NODE.increaseBlockQps(count);
}
// 处理注册entry回调任务的通过事件
for (ProcessorSlotEntryCallback<DefaultNode> handler : StatisticSlotCallbackRegistry.getEntryCallbacks()) {
handler.onBlocked(e, context, resourceWrapper, node, count, args);
}
throw e;
} catch (Throwable e) {
// 未知的错误
context.getCurEntry().setError(e);
// 更新异常QPS数量
node.increaseExceptionQps(count);
// 更新origin node的数据
if (context.getCurEntry().getOriginNode() != null) {
context.getCurEntry().getOriginNode().increaseExceptionQps(count);
}
if (resourceWrapper.getType() == EntryType.IN) {
// 更新inbound类型请求的全局数据
Constants.ENTRY_NODE.increaseExceptionQps(count);
}
throw e;
}
}
它其实是一个后置统计过程,相当于我们的请求已经成功通过网关的校验,可以正常执行,我们需要对计数器等进行操作。
- 首先,它会继续后续的slot处理,等待正常的返回结果。
- 如果正常返回,先更新当前node的请求数量、请求通过数,然后更新请求OriginNode的请求线程数和请求通过数,如果是inbound类型的请求,还会更新全局的请求数据,最后处理获取entry成功的回调任务。
- 如果开启了优先级策略,Sentinel判定可以进行等待,更新请求线程数即可。
- 如果捕获到了BlockException,证明当前请求被Sentinel拒绝,我们需要更新异常数据。
- 未知错误的情况下,我们也需要更新异常数据。
- 在BlockException和未知异常的情况下,都需要抛出异常,供CtSph进行处理。
SystemSlot
SystemSlot用于校验当前系统数据指标是否超出阈值。
SystemSlot#entry()
我们继续来看SystemSlot#entry()的执行逻辑:
@Override
public void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node, int count,
boolean prioritized, Object... args) throws Throwable {
SystemRuleManager.checkSystem(resourceWrapper);
fireEntry(context, resourceWrapper, node, count, prioritized, args);
}
- 通过系统规则校验器校验系统数据指标阈值。
- 执行下一个slot的逻辑。
SystemRuleManager#checkSystem
public static void checkSystem(ResourceWrapper resourceWrapper) throws BlockException {
// 确认是否开启系统规则校验,默认关闭
if (!checkSystemStatus.get()) {
return;
}
// 系统规则仅用于inbound流量
if (resourceWrapper.getType() != EntryType.IN) {
return;
}
// 校验当前QPS是否超出阈值
double currentQps = Constants.ENTRY_NODE == null ? 0.0 : Constants.ENTRY_NODE.successQps();
if (currentQps > qps) {
throw new SystemBlockException(resourceWrapper.getName(), "qps");
}
// 校验当前请求线程数是否超出阈值
int currentThread = Constants.ENTRY_NODE == null ? 0 : Constants.ENTRY_NODE.curThreadNum();
if (currentThread > maxThread) {
throw new SystemBlockException(resourceWrapper.getName(), "thread");
}
// 校验当前平均响应时间是否超出阈值
double rt = Constants.ENTRY_NODE == null ? 0 : Constants.ENTRY_NODE.avgRt();
if (rt > maxRt) {
throw new SystemBlockException(resourceWrapper.getName(), "rt");
}
// 校验当前系统负载是否超出阈值
if (highestSystemLoadIsSet && getCurrentSystemAvgLoad() > highestSystemLoad) {
if (!checkBbr(currentThread)) {
throw new SystemBlockException(resourceWrapper.getName(), "load");
}
}
// 校验当前CPU使用率是否超出阈值
if (highestCpuUsageIsSet && getCurrentCpuUsage() > highestCpuUsage) {
if (!checkBbr(currentThread)) {
throw new SystemBlockException(resourceWrapper.getName(), "cpu");
}
}
}
SystemCheckManager#checkSystem()用于校验inbound流量对系统的压力是否超出阈值。
它会对当前对系统请求QPS、请求线程数、整体平均响应时间、系统负载、CPU使用率进行检查。
系统检查规则默认是关闭的。
接下来进入具体的网关规则检查。
AuthoritySlot
AuthoritySlot就是我们经常使用到的黑白名单模式,所以它会非常依赖originName,也就是我们的请求来源应用名称。
AuthoritySlot#entry()
我们继续来看AuthoritySlot#entry()的执行逻辑:
@Override
public void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node, int count, boolean prioritized, Object... args)
throws Throwable {
checkBlackWhiteAuthority(resourceWrapper, context);
fireEntry(context, resourceWrapper, node, count, prioritized, args);
}
- 进行黑白名单权限校验。
- 执行下一个slot的逻辑。
AuthoritySlot#checkBlackWhiteAuthority()
我们继续来看具体的黑白名单校验逻辑:
void checkBlackWhiteAuthority(ResourceWrapper resource, Context context) throws AuthorityException {
// 获取所有AuthorityRule
Map<String, Set<AuthorityRule>> authorityRules = AuthorityRuleManager.getAuthorityRules();
if (authorityRules == null) {
return;
}
// 获取指定resource的AuthorityRule集合
Set<AuthorityRule> rules = authorityRules.get(resource.getName());
if (rules == null) {
return;
}
for (AuthorityRule rule : rules) {
// 对于所有的AuthorityRule,进行规则检查
if (!AuthorityRuleChecker.passCheck(rule, context)) {
throw new AuthorityException(context.getOrigin(), rule);
}
}
}
- 首先,获取系统缓存的所有的权限规则。
- 接着,获取针对当前resource的所有权限规则。
- 然后,对当前resource的所有权限规则进行遍历,通过权限规则校验器进行检查。
- 如果命中了权限规则范围,则抛出AuthorityException异常。
AuthorityRuleChecker#passCheck()
我们继续来看针对每个权限规则的具体校验逻辑:
static boolean passCheck(AuthorityRule rule, Context context) {
// 获取当前请求的origin名称
String requester = context.getOrigin();
// origin名称为空或者没有限制应用,直接判断通过权限规则校验
if (StringUtil.isEmpty(requester) || StringUtil.isEmpty(rule.getLimitApp())) {
return true;
}
// 进行名称全匹配搜索
int pos = rule.getLimitApp().indexOf(requester);
boolean contain = pos > -1;
// 如果包含,就会进行精确匹配搜索
if (contain) {
boolean exactlyMatch = false;
String[] appArray = rule.getLimitApp().split(",");
for (String app : appArray) {
if (requester.equals(app)) {
exactlyMatch = true;
break;
}
}
contain = exactlyMatch;
}
// 获取权限策略方式
int strategy = rule.getStrategy();
// 如果策略是黑名单方式,并且包含当前请求的origin,权限规则校验不通过,返回false
if (strategy == RuleConstant.AUTHORITY_BLACK && contain) {
return false;
}
// 如果策略是白名单方式,并且不包含当前请求的origin,权限规则校验不通过,返回false
if (strategy == RuleConstant.AUTHORITY_WHITE && !contain) {
return false;
}
// 其他情况下,通过权限规则校验,返回true
return true;
}
- 首先,想要使用权限规则,我们的请求就必须带有请求的应用名称。
- 其次,会进行一次全局的索引搜索,如果存在需要进行限制的应用名称,才会分离所有的应用名称,进行精确匹配。
- 然后,根据权限规则的策略方式,对黑、白两种方式进行不同的校验。
- 如果策略是黑名单方式,并且包含当前请求的应用名称,则也判定权限校验规则不通过。
- 如果策略是白名单方式,并且不包含当前请求的应用名称,则判定权限规则校验不通过。
- 其他情况下,均判定为通过权限规则校验。
先进行全局搜索的原因在于避免每次都进行for循环操作,降低时间复杂度。
FlowSlot
FlowSlot#entry()
我们继续来看FlowSlot#entry()的执行逻辑:
@Override
public void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node, int count,
boolean prioritized, Object... args) throws Throwable {
checkFlow(resourceWrapper, context, node, count, prioritized);
fireEntry(context, resourceWrapper, node, count, prioritized, args);
}
- 进行流控规则校验。
- 执行下一个slot的逻辑。
FlowRuleChecker#checkFlow()
我们继续看流控规则的校验逻辑:
void checkFlow(ResourceWrapper resource, Context context, DefaultNode node, int count, boolean prioritized)
throws BlockException {
checker.checkFlow(ruleProvider, resource, context, node, count, prioritized);
}
public void checkFlow(Function<String, Collection<FlowRule>> ruleProvider, ResourceWrapper resource,
Context context, DefaultNode node, int count, boolean prioritized) throws BlockException {
if (ruleProvider == null || resource == null) {
return;
}
// 获取当前resource的所有流控规则集合
Collection<FlowRule> rules = ruleProvider.apply(resource.getName());
if (rules != null) {
// 遍历并校验
for (FlowRule rule : rules) {
if (!canPassCheck(rule, context, node, count, prioritized)) {
throw new FlowException(rule.getLimitApp(), rule);
}
}
}
}
- 获取当前resource关联的流控规则。
- 遍历关联的每个流控规则,并进行校验。
继续来看#canPassCheck()方法:
public boolean canPassCheck(/*@NonNull*/ FlowRule rule, Context context, DefaultNode node, int acquireCount, boolean prioritized) {
String limitApp = rule.getLimitApp();
if (limitApp == null) {
return true;
}
// 开启集群模式,进行集群模式校验
if (rule.isClusterMode()) {
return passClusterCheck(rule, context, node, acquireCount, prioritized);
}
// 进行本地流控校验
return passLocalCheck(rule, context, node, acquireCount, prioritized);
}
- 对规则限制的应用进行校验,默认的流控规则的应用名称是default,意为对所有的应用都进行规则限制。
- 如果开启了集群模式,将使用集群规则校验模式进行规则校验。
- 否则,使用本地校验模式进行规则校验。
FlowRuleChecker#passClusterCheck()
我们继续来看集群模式的校验逻辑:
private static boolean passClusterCheck(FlowRule rule, Context context, DefaultNode node, int acquireCount,
boolean prioritized) {
try {
TokenService clusterService = pickClusterService();
// 如果没有集群服务,降级到校验本地流控校验
if (clusterService == null) {
return fallbackToLocalOrPass(rule, context, node, acquireCount, prioritized);
}
// 获取flowId
long flowId = rule.getClusterConfig().getFlowId();
// 请求服务端,进行流控校验
TokenResult result = clusterService.requestToken(flowId, acquireCount, prioritized);
return applyTokenResult(result, rule, context, node, acquireCount, prioritized);
} catch (Throwable ex) {
RecordLog.warn("[FlowRuleChecker] Request cluster token unexpected failed", ex);
}
// 降级到本地流控校验,如果规则的服务端或者客户端不可用
// 如果降级服务也不可用,直接判定为通过
return fallbackToLocalOrPass(rule, context, node, acquireCount, prioritized);
}
- 由于是集群模式,我们需要向Token Server节点请求token,请求token首先就需要获取发送请求的client。
- 如果没有可用的client,Sentinel就会降级到本地规则校验逻辑。
- 构建token请求body,并发送请求。
- 处理请求结果。
FlowRuleChecker#fallbackToLocalOrPass()
我们j继续来看集群模式降级为本地模式的逻辑:
private static boolean fallbackToLocalOrPass(FlowRule rule, Context context, DefaultNode node, int acquireCount,
boolean prioritized) {
// 集群开启了如果请求失败,就降级到本地流控规则校验策略
if (rule.getClusterConfig().isFallbackToLocalWhenFail()) {
// 本地校验流控规则
return passLocalCheck(rule, context, node, acquireCount, prioritized);
} else {
// 至此,流控规则不会生效,直接通过
return true;
}
}
- 集群模式降级策略通过fallbackToLocalWhenFail属性进行控制,如果开启降级本地策略,则会调用FlowRuleChecker#passLocalCheck()进行处理。
- 没有开启集群降级至本地策略,直接判定为通过。
FlowRuleChecker#passLocalCheck()
我们继续来看本地流控规则校验逻辑:
private static boolean passLocalCheck(FlowRule rule, Context context, DefaultNode node, int acquireCount, prioritized) {
Node selectedNode = selectNodeByRequesterAndStrategy(rule, context, node);
if (selectedNode == null) {
return true;
}
return rule.getRater().canPass(selectedNode, acquireCount, prioritized);
}
- 首先,需要选择流控数据来源数据统计节点。
- 然后,以数据统计节点的数据为基准,以获取的token数量为需求,进行流控规则的校验。
FlowRuleChecker#selectNodeByRequesterAndStrategy()
我们继续来看数据节点的选取逻辑,通过上一节的介绍,我们了解到,DefaultNode和ClusterNode都可以进行数据统计,而我们还可以设置不同的流控策略:
static Node selectNodeByRequesterAndStrategy(/*@NonNull*/ FlowRule rule, Context context, DefaultNode node) {
// 必须参数校验
String limitApp = rule.getLimitApp();
int strategy = rule.getStrategy();
String origin = context.getOrigin();
// 如果origin名称指定了除"default"或"other"之外的origin名称
if (limitApp.equals(origin) && filterOrigin(origin)) {
// 并且策略是直接流控控制
if (strategy == RuleConstant.STRATEGY_DIRECT) {
// 直接返回当前上下文正在处理的数据统计节点
return context.getOriginNode();
}
// 否则,使用关联的数据统计节点
return selectReferenceNode(rule, context, node);
} else if (RuleConstant.LIMIT_APP_DEFAULT.equals(limitApp)) {
// 如果origin名称范围是"default"
if (strategy == RuleConstant.STRATEGY_DIRECT) {
// 并且策略是直接流控控制,直接返回ClusterNode作为数据统计节点
return node.getClusterNode();
}
// 否则,使用关联的数据统计节点
return selectReferenceNode(rule, context, node);
} else if (RuleConstant.LIMIT_APP_OTHER.equals(limitApp)
&& FlowRuleManager.isOtherOrigin(origin, rule.getResource())) {
// 并且策略是直接流控控制,直接返回当前上下文正在处理的数据统计节点
if (strategy == RuleConstant.STRATEGY_DIRECT) {
return context.getOriginNode();
}
// 否则,使用关联的数据统计节点
return selectReferenceNode(rule, context, node);
}
// 策略校验没有通过,没有获取到数据统计节点
return null;
}
- 首先,对origin名称、流控策略、流控限制origin范围进行校验。
- 如果流控规则对自定义origin进行了限制:
- 如果流控策略是直接流控控制,则返回当前上下文使用的数据统计节点。
- 否则,使用关联的数据统计节点。
- 如果流控规则是默认的针对所有的请求来源:
- 如果流控策略是直接流控控制,则使用ClusterNode作为数据统计节点。
- 否则,使用关联的数据统计节点。
- 如果流控规则是针对其他请求来源,并且当前请求属于其他请求来源的指定范围内。
- 如果策略是直接流控控制,则返回当前上下文正在处理的数据统计节点。
- 否则,使用关联的数据统计节点
- 至此,策略校验没有通过,没有获取到数据统计节点。
没有数据统计节点,Sentinel不会进行流控。
FlowRuleChecker#selectReferenceNode()
我们继续来看如何选择关联的数据统计节点:
static Node selectReferenceNode(FlowRule rule, Context context, DefaultNode node) {
// 获取当前resource关联的resource
String refResource = rule.getRefResource();
// 获取当前resource规则的流控策略
int strategy = rule.getStrategy();
// 如果没有关联resource,视为没有数据统计节点
if (StringUtil.isEmpty(refResource)) {
return null;
}
// 如果流控策略是关联流控策略,则使用关联resource的ClusterNode作为数据统计节点
if (strategy == RuleConstant.STRATEGY_RELATE) {
return ClusterBuilderSlot.getClusterNode(refResource);
}
// 如果流控策略是链式流控策略
if (strategy == RuleConstant.STRATEGY_CHAIN) {
// 如果链式调用并不在同一个Context中,则无法获取数据统计节点
if (!refResource.equals(context.getName())) {
return null;
}
// 否则使用当前Context使用的数据统计节点
return node;
}
// 没有找到合法的节点,返回null
return null;
}
- 首先,此时仅会存在两种策略,关联流控策略和链式流控策略,这两种策略都与refResource属性,也就是关联的resource有关,所以需要对refResource属性进行校验。
- 如果流控策略是关联流控策略,则使用关联resource的ClusterNode作为数据统计节点。
- 如果流控策略是链式流控策略:
- 如果链式调用并不在同一个Context中,则无法获取数据统计节点。
- 否则使用当前Context使用的数据统计节点。
- 至此,没有找到合法的数据统计节点。
获取到了数据统计节点,接下来就会针对不同的流量整形策略,进行不同的流控处理逻辑。
流量整形处理逻辑
Sentinel中流量整形通过TrafficShapingController来实现,
DefaultController
我们来看直接拒绝策略的流控规则校验:
@Override
public boolean canPass(Node node, int acquireCount, boolean prioritized) {
// 当前已经被获取的token数量
int curCount = avgUsedTokens(node);
// 已经被获取的token数量+本次请求即将获取的数量超出了流控规则设置的阈值
if (curCount + acquireCount > count) {
// 如果请求开启了优先级策略,并且流控等级为QPS限流
if (prioritized && grade == RuleConstant.FLOW_GRADE_QPS) {
long currentTime;
long waitInMs;
// 获取当前时间戳
currentTime = TimeUtil.currentTimeMillis();
// 获取排队等待时间
waitInMs = node.tryOccupyNext(currentTime, acquireCount, count);
// 如果等待时间处于设置的可等待的时间范围内
if (waitInMs < OccupyTimeoutProperty.getOccupyTimeout()) {
// 进行等待
node.addWaitingRequest(currentTime + waitInMs, acquireCount);
node.addOccupiedPass(acquireCount);
sleep(waitInMs);
// PriorityWaitException意味着请求将会在等待{@link @waitInMs}时间之后判定通过
throw new PriorityWaitException(waitInMs);
}
}
// 否则判定不通过此流控规则
return false;
}
return true;
}
- 首先,获取已经被获取的token数量。
- 如果当前已经被获取的token+本次请求需要获取的token数量,超出了流控规则设置的阈值:
- 在没有开启优先级策略的情况下,判定命中流控规则,进行阻塞。
- 在开启优先级策略的情况下,需要获取当前滑动窗口需要进行等待的时间,进行等待后,判定请求通过,抛出PriorityWaitException异常。
- 如果当前已经被获取的token+本次请求需要获取的token数量,没有超出了流控规则设置的阈值,则判定通过此流控规则。
WarmUpController
我们来看预热模式的流控规则校验:
WarmUpController#canPass()
@Override
public boolean canPass(Node node, int acquireCount, boolean prioritized) {
long passQps = (long) node.passQps();
long previousQps = (long) node.previousPassQps();
syncToken(previousQps);
// 开始计算它的斜率
// 如果进入了警戒线,开始调整他的qps
long restToken = storedTokens.get();
if (restToken >= warningToken) {
long aboveToken = restToken - warningToken;
// 消耗的速度要比warning快,但是要比慢
// current interval = restToken*slope+1/count
// 通过计算当前可用token和警戒线的距离,来计算当前的QPS
// aboveToken * slope + 1.0 / count = 处于预热区内,当前比率下,获取token的时间
// 1/获取token的时间,即为当前的QPS
double warningQps = Math.nextUp(1.0 / (aboveToken * slope + 1.0 / count));
if (passQps + acquireCount <= warningQps) {
return true;
}
} else {
// 如果处于热区域内,没有超过规则设定的阈值,则判定通过
if (passQps + acquireCount <= count) {
return true;
}
}
// 否则,判定不通过
return false;
}
- 首先,获取当前QPS和上一秒的QPS,针对上一秒的QPS,更新可获取的token数量。
- 如果剩余的token数量进入了预热区,我们需要计算当前的预热QPS,如果当前QPS+本次需要获取的token数量没有过预热QPS,证明是在预热区内是可以接受本次请求的,判定通过。
- 如果处于热区域内,没有超过规则设定的阈值,也判定通过。
- 其他情况,均判定不通过。
WarmUpController#syncToken()
我们继续来看扩容token数量的逻辑:
protected void syncToken(long passQps) {
// 获取当前的时间戳
long currentTime = TimeUtil.currentTimeMillis();
// 精确到秒的时间戳
currentTime = currentTime - currentTime % 1000;
// 获取上一次扩容的时间
long oldLastFillTime = lastFilledTime.get();
// 如果时间不对,不进行同步
if (currentTime <= oldLastFillTime) {
return;
}
// token数量旧值
long oldValue = storedTokens.get();
// 计算新的token数量
long newValue = coolDownTokens(currentTime, passQps);
// 更新token的值
if (storedTokens.compareAndSet(oldValue, newValue)) {
// 更新当前可用的值
long currentValue = storedTokens.addAndGet(0 - passQps);
if (currentValue < 0) {
storedTokens.set(0L);
}
// 设置上一次扩容的时间戳
lastFilledTime.set(currentTime);
}
}
- 首先,token数量的添加,要以过去的秒时间单位进行统计。
- 其次,我们需要获取上一次进行扩容token的去掉毫秒位的时间戳已经当前去掉毫秒位的时间戳。
- 通过预热和非预热模式来决定扩容的token数量。
- 更新剩余的token数量和更新时间戳。
WarmUpController#coolDownTokens()
我们继续来看获取扩充token数量的逻辑:
private long coolDownTokens(long currentTime, long passQps) {
long oldValue = storedTokens.get();
long newValue = oldValue;
// 添加token的判断前提条件:
// 当token的消耗程度远远低于警戒线的时候
if (oldValue < warningToken) {
// 处于长方形区域内,属于热区,正常添加token
// 根据count数,每秒扩充token
newValue = (long)(oldValue + (currentTime - lastFilledTime.get()) * count / 1000);
} else if (oldValue > warningToken) {
// 当前判定仍处于冷启动阶段
// 太绕了,我佛了
// 当前最慢的QPS计算公式:1 / (coldFactor * (1 / count)) => count / coldFactor
// 当前的QPS已经比最慢的还慢了,需要添加token
if (passQps < (int)count / coldFactor) {
// 否则就需要添加token
newValue = (long)(oldValue + (currentTime - lastFilledTime.get()) * count / 1000);
}
}
// 取计算出的token新值和容量上限的二者的最小值
return Math.min(newValue, maxToken);
}
- 当token处于热区域内时,证明服务处于正常状态,按照已经过去的秒级时间正常扩充即可。
- 当token处于预热区域内时,首先我们需要计算出最慢的QPS,如果当前QPS已经比最慢的QPS还慢了,则需要添加token。
- token总数量不能超过maxToken的上限。
预热策略需要注意计算公式。
RateLimiterController
我们来看匀速排队策略的实现:
RateLimiterController#canPass()
@Override
public boolean canPass(Node node, int acquireCount, boolean prioritized) {
// 如果请求的token是非正整数,直接通过
if (acquireCount <= 0) {
return true;
}
// 如果当前可获取的token数量是非正整数,判定不通过
// 否则,costTime的计算将是最大的,并且在某些情况下,等待时间会溢出
if (count <= 0) {
return false;
}
// 获取当前的时间戳
long currentTime = TimeUtil.currentTimeMillis();
// 计算两次请求之间的时间差,把请求均匀分在1s上
long costTime = Math.round(1.0 * (acquireCount) / count * 1000);
// 当前请求预期通过的时间戳
long expectedTime = costTime + latestPassedTime.get();
// 如果预期通过的时间不是未来的时间戳
if (expectedTime <= currentTime) {
// 更新上一次通过的时间,本次请求通过
latestPassedTime.set(currentTime);
return true;
} else {
// 如果期待的时间是在未来的时间戳
// 计算等待时间
long waitTime = costTime + latestPassedTime.get() - TimeUtil.currentTimeMillis();
// 如果等待时间大于等待时间,判定不通过
if (waitTime > maxQueueingTimeMs) {
return false;
} else {
// 上次时间+本次需要耗费的时间
long oldTime = latestPassedTime.addAndGet(costTime);
try {
// 获取最新的等待时间
waitTime = oldTime - TimeUtil.currentTimeMillis();
// 再次判断下是否超过最大等待时间
if (waitTime > maxQueueingTimeMs) {
// 需要阻塞,将上次通过的时间改回去
// 刚开始认为这是个bug,后来了解到
// 每个请求在设置oldTime时都会通过addAndGet()原子操作lastestPassedTime,并赋值给oldTime
// 这样每个线程的sleep()时间都不相同,线程也不会同时醒过来
// costTime+latestPassedTime,大于当前时间就代表请求的比较频繁,需要等待一会才能继续请求
latestPassedTime.addAndGet(-costTime);
return false;
}
// 在条件竞争中,等待时间很可能是非正整数,
if (waitTime > 0) {
// 如果可以等待,则等待相应时间
Thread.sleep(waitTime);
}
// 如果等待时间是非负整数,无需等待,直接判定通过
// 判定通过
return true;
} catch (InterruptedException e) {
}
}
}
// 其余情况,判定为不通过
return false;
}
- 首先,对请求的token数量,当前可获取的token数量进行校验。
- 然后,计算两次请求之间的时间差,将请求的token数量均匀分布在1s上,计算出的请求时间差+上一次请求通过的时间就是本次请求预期通过的时间。
- 如果预期通过的时间,小于当前时间戳,证明剩余可获取的token满足本次请求获取token的数量,直接判定通过,否则就需要排队等待。
- 首先计算当前请求获取给定token数量还需要等待的时间,如果等待时间大于排队时间,则无法进行排队,直接判定不通过。
- 如果可以进行排队,重新判断一下是否进行排队,如果仍可进行排队,则当前请求占有了队列中的位置,在等待时间内进行等待后,判定通过。
- 如果不可以进行排队,则将最后一次通过请求的时间戳更新为上一次通过请求的时间戳,判定不通过。
这里有一个很巧妙的设计,每次请求在设置oldTime时,都会通过addAndGet()原子操作lastestPassedTime,这样每个线程的sleep()时间都不相同,线程大概率不会同时醒过来。
WarmUpRateLimiterController
与WarmUpController和RateLimiterController代码类似,可以自行查看。
我们默认可以通过http://localhost:8719/tree地址来查看每个资源的实时统计,也可以在Dashboard进行查看。
DegradeSlot
DegradeSlot用于对降级规则进行校验。
DegradeSlot#entry()
我们继续来看DegradeSlot#entry()的执行逻辑:
@Override
public void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node, int count, boolean prioritized, Object... args)
throws Throwable {
// 校验降级规则
DegradeRuleManager.checkDegrade(resourceWrapper, context, node, count);
// 进行下一个ProcessorSlot
fireEntry(context, resourceWrapper, node, count, prioritized, args);
}
- 进行降级规则校验。
- 执行下一个slot的逻辑。
DegradeRuleManger#checkDegrade()
我们继续来降级规则的校验逻辑:
public static void checkDegrade(ResourceWrapper resource, Context context, DefaultNode node, int count)
throws BlockException {
// 获取当前resource的所有降级规则
Set<DegradeRule> rules = degradeRules.get(resource.getName());
if (rules == null) {
return;
}
// 遍历每个降级规则,分别进行检查
for (DegradeRule rule : rules) {
if (!rule.passCheck(context, node, count)) {
// 命中降级规则,抛出DegradeException
throw new DegradeException(rule.getLimitApp(), rule);
}
}
}
- 首先,从缓存的全量降级集合中获取当前resource的降级规则。
- 其次,遍历每个降级规则,分别进行降级规则检查。
- 最后,如果命中了降级规则,抛出DegradeException。
DegradeRule#passCheck()
我们继续来看降级规则的对降级的处理逻辑:
@Override
public boolean passCheck(Context context, DefaultNode node, int acquireCount, Object... args) {
// 获取乐观锁
if (cut.get()) {
return false;
}
// 获取ClusterNode,用于提供Cluster数据信息
ClusterNode clusterNode = ClusterBuilderSlot.getClusterNode(this.getResource());
if (clusterNode == null) {
return true;
}
if (grade == RuleConstant.DEGRADE_GRADE_RT) {
// 响应时间降级策略
// 从ClusterNode获取实时统计的成功请求的平均响应时间
double rt = clusterNode.avgRt();
// 如果计算出的平均响应时间小于阈值,判定通过
if (rt < this.count) {
passCount.set(0);
return true;
}
// 否则一经超过阈值,将启动降级策略
// 如果接下来的五次请求依然超出了阈值,才会走最后的降级策略
if (passCount.incrementAndGet() < RT_MAX_EXCEED_N) {
// 接下来的五次请求,如果没有超过阈值,那么依然会判定通过降级检查
return true;
}
} else if (grade == RuleConstant.DEGRADE_GRADE_EXCEPTION_RATIO) {
// 异常比率策略
// 获取当前resource的发生异常QPS
double exception = clusterNode.exceptionQps();
// 获取当前resource的成功请求QPS
double success = clusterNode.successQps();
// 获取当前resource的总QPS
double total = clusterNode.totalQps();
// 如果总QPS小于阈值上线,判定通过降级规则检查
if (total < RT_MAX_EXCEED_N) {
return true;
}
// 真正成功的请求数=成功请求数-异常请求数
double realSuccess = success - exception;
// 如果没有真正成功的请求数,并且异常数量小于设定的阈值
if (realSuccess <= 0 && exception < RT_MAX_EXCEED_N) {
// 判定通过降级规则检查
return true;
}
// 如果异常比率占成功比率,没有超过设定的阈值
if (exception / success < count) {
// 判定通过降级规则检查
return true;
}
} else if (grade == RuleConstant.DEGRADE_GRADE_EXCEPTION_COUNT) {
// 获取当前resource出现的异常数量,统计的是每分钟的数量
double exception = clusterNode.totalException();
// 如果resource每分钟的异常数量没有超出设定的阈值
if (exception < count) {
// 判定通过降级规则检查
return true;
}
}
// 总结一下,只有在以下情况会走到这里
// 平均响应时间:计算的平均响应时间大于阈值,接下来的五次请求也已经超过缓冲的阈值
// 异常比率:每秒钟出现的异常数量已经超过设定的阈值,有真正成功的请求,或者异常数量超过缓冲的异常数量
// 异常数量:每分钟出现的异常数量已经超过阈值
// 首先乐观锁设置为不可用
if (cut.compareAndSet(false, true)) {
// 需要进行重置
ResetTask resetTask = new ResetTask(this);
// 根据降级时间进行恢复
pool.schedule(resetTask, timeWindow, TimeUnit.SECONDS);
}
return false;
}
- 首先,降级数据信息来源只会来源于ClusterNode,因为降级只和resource全局的信息有关。
- 如果设置的降级策略是根据平均响应时长,我们会根据ClusterNode提供的平均响应时长进行判定:
- 在设定的阈值范围内,判定通过。
- 否则,在接下来的五次请求,如果没有超过设定的阈值,那么也判定通过。
- 其他情况下,判定不通过。
- 如果设置的降级策略是根据出现异常比率,我们会从ClusterNode中分别获取异常请求QPS、成功请求QPS、总QPS:
- 如果总的QPS还没有超过设定的阈值,直接判定通过。
- 如果没有真正成功的请求,并且出现异常的请求数量没有超过Sentinel设定的阈值,判定通过。
- 前面均是针对异常请求QPS的限制,此时开始计算比率,如果异常QPS/成功QPS,小于设定的阈值,判定通过。
- 其他情况,均判定不通过。
- 如果设置的降级策略是根据异常个数,则统计每分钟出现的异常数量,没有超出设定的阈值,判定通过。
- 以上没有判定通过的情况,均会走到这里,也就是对当前窗口的数据进行重置:
- 平均响应时间:计算的平均响应时间大于阈值,接下来的五次请求也已经超过缓冲的阈值。
- 异常比率:每秒钟出现的异常数量已经超过设定的阈值,有真正成功的请求,或者异常数量超过缓冲的异常数量。
- 异常数量:每分钟出现的异常数量已经超过阈值。
重置时,由于开启了乐观锁,所以所有请求都判定为不通过,服务将在降级恢复时间内重置完成后恢复。
在异常比率降级策略中,异常QPS、成功请求QPS和总QPS,都是异常数量/窗口时间间隔,单位秒。

