 随遇而安
随遇而安在对Zuul 2.x的启动原理进行分析时,我们在配置文件中看到过这样一项配置:
{origin.name}.ribbon.listOfServers=127.0.0.1:10001,127.0.0.1:10002
此配置,让我们实现了对origin选取的策略。
不难看出,实现这种轮询策略的关键词是:ribbon。
1 Ribbon
Ribbon是Netflix开源的,用于提供云端负载均衡的组件,自Zuul 1.x开始使用。
可能你马上联系到另一个项目:Spring Cloud Ribbon。
但其实二者并不是一个项目,准确来说,Spring Cloud Ribbon实现了Netflix Ribbon的绝大部分功能。
2 Ribbon核心组件
2.1 ribbon-core
ribbon-core主要用于管理客户端配置、请求、响应等。
核心类IClientConfig:
public interface IClientConfig {
String getClientName();
String getNameSpace();
void setNameSpace(String nameSpace);
/**
* 加载指定客户端或负载均衡器的配置文件
* @param clientName
*/
void loadProperties(String clientName);
/**
* 为配置加载默认值
*/
void loadDefaultValues();
Map<String, Object> getProperties();
...
class Builder {
...
private IClientConfig config;
Builder() {
}
/**
* 建造者模式
*/
public static Builder newBuilder() {
Builder builder = new Builder();
builder.config = ClientConfigFactory.findDefaultConfigFactory().newConfig();
return builder;
}
/**
* Archaius是Netflix开源的属性管理
* ${clientName}.ribbon是默认的前缀名称
* @param clientName
*/
public static Builder newBuilder(String clientName) {
Builder builder = new Builder();
builder.config = ClientConfigFactory.findDefaultConfigFactory().newConfig();
builder.config.loadProperties(clientName);
return builder;
}
...
}
}
IClientConfig主要为客户端的配置管理提供了抽象服务,同时也声明了一个建造者,用于构建配置。
在微服务中,一般情况下,clientName指的是spring.application.name,如果没有配置这个值,那么会影响到所有的客户端配置。
IClientConfig使用工厂模式进行创建,载体是ClientConfigFactory:
public interface ClientConfigFactory {
IClientConfig newConfig();
ClientConfigFactory DEFAULT = findDefaultConfigFactory();
default int getPriority() {
return 0;
}
/**
* 只取一个ClientConfigFactory
* 排序:优先级和类名
* @return
*/
static ClientConfigFactory findDefaultConfigFactory() {
return StreamSupport.stream(ServiceLoader.load(ClientConfigFactory.class).spliterator(), false)
.max(Comparator
.comparingInt(ClientConfigFactory::getPriority)
.thenComparing(Comparator.comparing(f -> f.getClass().getCanonicalName())))
.orElseGet(() -> {
throw new IllegalStateException("Expecting at least one implementation of ClientConfigFactory discoverable via the ServiceLoader");
});
}
}
而同时我们会发现在IClientConfig#Builder#newBuilder()方法中,也会调用findDefaultConfigFactory()方法。
该方法是使用SPI的方式实例化默认的客户端配置,这部分内容放置在ribbon-archaius中。
Archaius是Netflix开源的动态配置管理服务。
而SPI所需services是在ribbon-archaius中:
com.netflix.client.config.ArchaiusClientConfigFactory
public class ArchaiusClientConfigFactory implements ClientConfigFactory {
@Override
public IClientConfig newConfig() {
return new DefaultClientConfigImpl();
}
}
也就是我们在ClientConfigFactory中调用newConfig()时,实例化的是默认的配置DefaultClientConfigImpl():
public DefaultClientConfigImpl() {
this.dynamicProperties.clear();
this.enableDynamicProperties = false;
}
每次创建默认配置时,都会清空动态属性集合,并且不允许使用动态属性。
而在IClientConfig的建造者中,在使用工厂创建完成一个客户端配置后,紧接着就会加载属性:
public static Builder newBuilder(String clientName, String propertyNameSpace) {
Builder builder = new Builder();
builder.config = ClientConfigFactory.findDefaultConfigFactory().newConfig();
builder.config.setNameSpace(propertyNameSpace);
builder.config.loadProperties(clientName);
return builder;
}
DefaultClientConfigImpl#loadProperties():
@Override
public void loadProperties(String restClientName){
// 允许动态属性
enableDynamicProperties = true;
// 设置客户端名称
setClientName(restClientName);
// 加载默认属性
loadDefaultValues();
// 设置自定义配置信息
Configuration props = ConfigurationManager.getConfigInstance().subset(restClientName);
for (Iterator<String> keys = props.getKeys(); keys.hasNext(); ){
String key = keys.next();
String prop = key;
try {
if (prop.startsWith(getNameSpace())){
prop = prop.substring(getNameSpace().length() + 1);
}
setPropertyInternal(prop, getStringValue(props, key));
} catch (Exception ex) {
throw new RuntimeException(String.format("Property %s is invalid", prop));
}
}
}
源码分析:
- 设置客户端配置允许属性的动态变更,将刚刚关闭的属性重新打开。
- 设置客户端名称,相当于一个配置的全限定名。
- 加载默认的客户端配置。
- 获取全局配置信息,找到以clientName起始的所有信息,进行遍历和设置属性值。
上面讲的是核心的客户端配置类,同时ribbon-core还包括公共的属性key,主要的属性key有:
- listOfServers,你的服务实例集群列表。
- MaxHttpConnectionsPerHost,每个服务实例的最大Http连接数。
- MaxTotalHttpConnections,单客户端配置允许的最大Http连接总数。
- MaxConnectionsPerHost,每个服务实例的最大连接数。
- MaxTotalConnections,单客户端配置允许的最大连接数。
- PoolMaxThreads,连接池最大数量。
- PoolMinThreads,连接池最小数量。
- PoolKeepAliveTime,连接保活时间。
以上配置信息,均可以到CommonClientConfigKey中查阅。
同时,ribbon-core模块还包括SSL配置,请求体,响应体,重试机制,虚IP地址解析器等客户端核心需求类。
3 Ribbon负载均衡
3.1 负载均衡设计
再来看ribbon-loadbalancer模块,该模块集中了所有负载均衡需要用的组件。
如果需要进行负载均衡,就需一个组件用于管理、筛选集群,在Zuul中,负载均衡器的核心接口是ILoadBalancer:
/**
* 软件技术上的负载均衡器的接口
* 一个典型的负载均衡器,需要进行负载均衡的服务实例集群,一个可以从轮换中选择出一个典型的服务实例,和一个可以从服务实例集群中选择出一个服务实例的调用
*/
public interface ILoadBalancer {
public void addServers(List<Server> newServers);
public Server chooseServer(Object key);
public void markServerDown(Server server);
@Deprecated
public List<Server> getServerList(boolean availableOnly);
public List<Server> getReachableServers();
public List<Server> getAllServers();
}
ILoadBalancer中定义了我们用于负载均衡使用的全部接口,包括:添加集群,选择对应的服务实例,获取集群中所有的服务实例等。
负载均衡器的依赖关系如图所示:
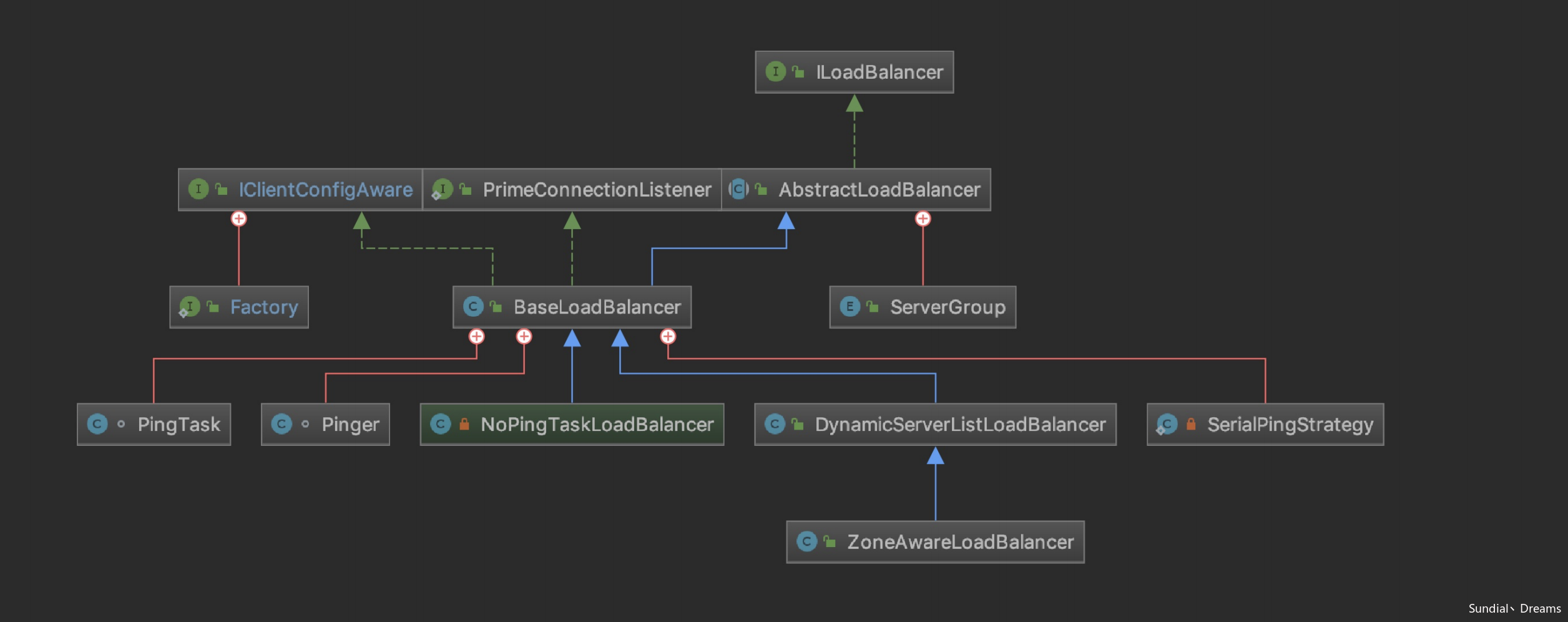
ribbon用一个超类实现了负载均衡器接口,同时也和集群类建立了联系,我们继续看AbstractLoadServer:
/**
* AbstractLoadBalancer包含了大多数负载均衡所需要的特性
* 1. 有一个指定标准的集群
* 2. 声明或者实现一个负载均衡策略
* 3. 可以在集群中找到适合的,可用的节点或者服务实例
*/
public abstract class AbstractLoadBalancer implements ILoadBalancer {
public enum ServerGroup{
ALL,
STATUS_UP,
STATUS_NOT_UP
}
/**
* 一个没有入参的服务实例选择
*/
public Server chooseServer() {
return chooseServer(null);
}
/**
* 获取负载均衡器负责管理的集群服务列表
*/
public abstract List<Server> getServerList(ServerGroup serverGroup);
/**
* 提供负载均衡器的数据分析
*/
public abstract LoadBalancerStats getLoadBalancerStats();
}
AbstractLoadServer中定义了作为负载均衡器需要实现的核心方法:
- 根据具体负载均衡策略实现,选取合适的负载均衡器。
- 获取当前负载均衡器进行管理的集群服务列表。
- 当前负载均衡器的数据统计分析。
如果我们没有实现自定义的负载均衡器,那么ribbon为我们准备了一个基础的负载均衡器,BaseLoadBalancer:
public class BaseLoadBalancer extends AbstractLoadBalancer implements
PrimeConnections.PrimeConnectionListener, IClientConfigAware {
BaseLoadBalancer是一个基础负载均衡器的实现,可以容纳任意一组服务实例集群,使用ping的方式来检查服务实例的存活状态。
还是同时维护了所有集群和可服务集群,可以满足不同的调用需求。
如果同时还没有ping策略以及负载均衡规则,BaseLoadBalancer也会为我们生成一套策略:
public BaseLoadBalancer() {
this.name = DEFAULT_NAME;
this.ping = null;
// ① 设置默认的负载均衡策略
setRule(DEFAULT_RULE);
// ② 设置ping任务
setupPingTask();
// ③ 创建负载均衡器状态监控
lbStats = new LoadBalancerStats(DEFAULT_NAME);
}
- 默认的负载均衡策略是我们熟知的Round-Robin策略。
- 使用java.util.Timer来实现一个定时执行ping任务的定时任务。
- 创建负载均衡器的状态监控对象,用于实时对负载均衡器进行监控、统计、数据分析,比如记录某个节点的请求总数。
而如果我们实现了ping动作的isAlive()接口,那么BaseLoadBalancer的默认ping策略是SerialPingStrategy,也就是我们常写的普通写法:
@Override
public boolean[] pingServers(IPing ping, Server[] servers) {
int numCandidates = servers.length;
boolean[] results = new boolean[numCandidates];
logger.debug("LoadBalancer: PingTask executing [{}] servers configured", numCandidates);
for (int i = 0; i < numCandidates; i++) {
// 默认集群状态时DEAD
results[i] = false;
try {
if (ping != null) {
results[i] = ping.isAlive(servers[i]);
}
} catch (Exception e) {
logger.error("Exception while pinging Server: '{}'", servers[i], e);
}
}
return results;
}
可以看出来,有很大的性能隐患。
3.2 服务过滤器
我们还会对服务实例集群进行筛选,核心接口是ServerListFilter:
/**
* 该接口允许筛选具有所需特性的,已配置的,或者是动态获取的候选服务实例集群
*/
public interface ServerListFilter<T extends Server> {
public List<T> getFilteredListOfServers(List<T> servers);
}
服务过滤器的示意图如下:
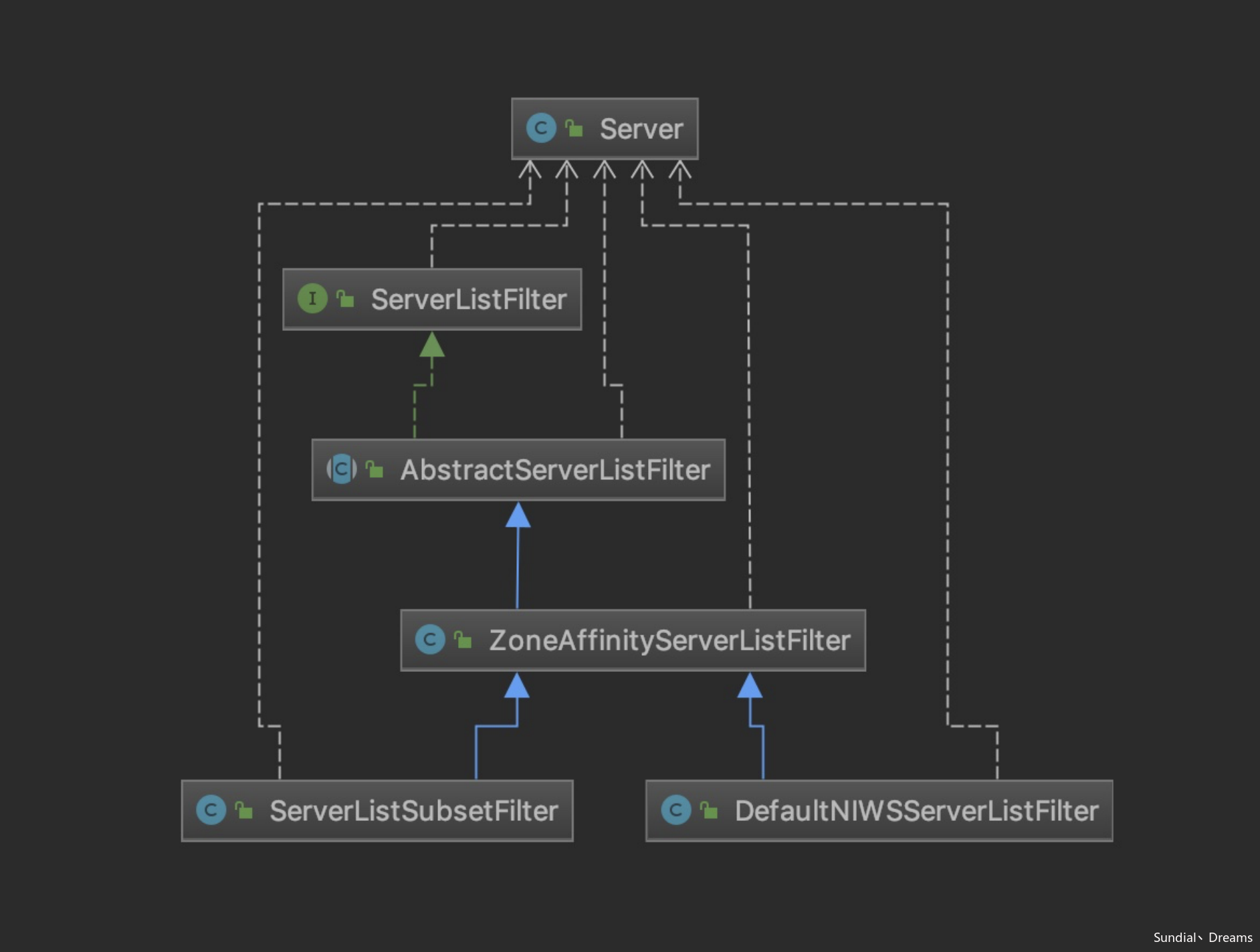
也有一个超类AbstractServerListFilter实现了服务过滤器接口:
/**
* 负责过滤从LoadBalancer的集群中过滤出符合条件的可用的服务实例
*/
public abstract class AbstractServerListFilter<T extends Server> implements ServerListFilter<T> {
private volatile LoadBalancerStats stats;
public void setLoadBalancerStats(LoadBalancerStats stats) {
this.stats = stats;
}
public LoadBalancerStats getLoadBalancerStats() {
return stats;
}
}
首先我们有一个基础的服务过滤器实现,ZoneAffinityServerListFilter:
/**
* 基于分区概念的服务过滤器
* 需要打开EnableZoneAffinity和EnableZoneExclusivity开关
* 意为同分区、同中心分配服务实例
* @author stonse
*
*/
public class ZoneAffinityServerListFilter<T extends Server> extends
AbstractServerListFilter<T> implements IClientConfigAware {
ZoneAffinityServerListFilter是根据同中心的策略来进行服务实例过滤的(因为Cloud Native基本上都是按中心分配的)。
我们来看一下该服务过滤器对服务过滤的实现,ZoneAffinityServerListFilter#getFilteredListOfServers():
@Override
public List<T> getFilteredListOfServers(List<T> servers) {
if (zone != null && (zoneAffinity || zoneExclusive) && servers !=null && servers.size() > 0){
// 过滤同中心服务实例
List<T> filteredServers = Lists.newArrayList(Iterables.filter(
servers, this.zoneAffinityPredicate.getServerOnlyPredicate()));
if (shouldEnableZoneAffinity(filteredServers)) {
return filteredServers;
} else if (zoneAffinity) {
overrideCounter.increment();
}
}
return servers;
}
- 通过断言的方式过滤同中心服务实例。
断言的过滤方法实现为,ZoneAffinityPredicate#apply():
@Override
public boolean apply(PredicateKey input) {
Server s = input.getServer();
String az = s.getZone();
if (az != null && zone != null && az.toLowerCase().equals(zone.toLowerCase())) {
return true;
} else {
return false;
}
}
断言方法是:从当前负载均衡环境中获取分区名称,和服务实例的名称进行对比。
ribbon也给出了服务过滤器的默认实现,ServerListSubsetFilter:
/**
* 负载均衡的集群是整个集群的子集,在集群规模很大的时非常有用,可以最大化利用http连接池,避免所有的连接都在一个池子中
* 它还可以通过网络故障和并发连接数来判断和摘除不健康的服务实例
*/
public class ServerListSubsetFilter<T extends Server> extends ZoneAffinityServerListFilter<T> implements IClientConfigAware, Comparator<T>{
}
ServerListSubsetFilter一般用于集群规模非常大,或者是涉及到跨分区集群的负载均衡体系。
同时也继承了ZoneAffinityServerListFilter类,也就是说会基于分区的服务过滤,继续做一些事情,我们看一下它实现的getFilteredListOfServers():
@Override
public List<T> getFilteredListOfServers(List<T> servers) {
// 先去获取同分区下的服务实例列表
List<T> zoneAffinityFiltered = super.getFilteredListOfServers(servers);
// 进行一次去重
Set<T> candidates = Sets.newHashSet(zoneAffinityFiltered);
// 当前服务实例子集
Set<T> newSubSet = Sets.newHashSet(currentSubset);
// 获取负载均衡器状态
LoadBalancerStats lbStats = getLoadBalancerStats();
for (T server: currentSubset) {
// 遍历所有的集群,删除没有从分区中查出来的集群
if (!candidates.contains(server)) {
newSubSet.remove(server);
} else {
// 从负载均衡器状态中获取当前服务实例的状态
ServerStats stats = lbStats.getSingleServerStat(server);
// 去除不满足服务状态的服务集群
if (stats.getActiveRequestsCount() > eliminationConnectionCountThreshold.get()
|| stats.getFailureCount() > eliminationFailureCountThreshold.get()) {
newSubSet.remove(server);
// 分区列表同时也删除对应的服务实例
candidates.remove(server);
}
}
}
// 子集群的大小
int targetedListSize = sizeProp.get();
// 看看摘除掉了多少个集群
int numEliminated = currentSubset.size() - newSubSet.size();
// 算一个最小摘除数
int minElimination = (int) (targetedListSize * eliminationPercent.get());
// 计算需要摘除的服务实例数量
int numToForceEliminate = 0;
if (targetedListSize < newSubSet.size()) {
numToForceEliminate = newSubSet.size() - targetedListSize;
} else if (minElimination > numEliminated) {
numToForceEliminate = minElimination - numEliminated;
}
if (numToForceEliminate > newSubSet.size()) {
numToForceEliminate = newSubSet.size();
}
// 如果需要摘除,排序后,从小到大进行摘除
if (numToForceEliminate > 0) {
List<T> sortedSubSet = Lists.newArrayList(newSubSet);
Collections.sort(sortedSubSet, this);
List<T> forceEliminated = sortedSubSet.subList(0, numToForceEliminate);
newSubSet.removeAll(forceEliminated);
candidates.removeAll(forceEliminated);
}
// 我们摘除后,需要进行一次服务实例补充,是从当前分区集群中随机选择机器进行补充
if (newSubSet.size() < targetedListSize) {
int numToChoose = targetedListSize - newSubSet.size();
candidates.removeAll(newSubSet);
if (numToChoose > candidates.size()) {
// Not enough healthy instances to choose, fallback to use the
// total server pool
candidates = Sets.newHashSet(zoneAffinityFiltered);
candidates.removeAll(newSubSet);
}
List<T> chosen = randomChoose(Lists.newArrayList(candidates), numToChoose);
for (T server: chosen) {
newSubSet.add(server);
}
}
// 重置当前子集群
currentSubset = newSubSet;
return Lists.newArrayList(newSubSet);
}
- 获取分区集群列表,同时删除已经摘除掉的机器。
- 如果需要进行机器摘除,计算摘除数量,将当前子集群进行排序后,按从小到大的顺序进行摘除。
- 如果未进行摘除,但是发现机器数量和集群数量不符时,需要随机的从当前分区集群里选出服务实例进行补充。
- 重置当前子集群。
和Kafka中的ISR和AR的概念类似。
3.3 负载均衡规则
负载均衡规则用于提供负载均衡的具体路由方式,比如我们常用的Round Robin策略,核心接口是IRule:
/**
* 为负载均衡声明一个规则接口
* 规则,可以是一种策略
* 比如众所周知的轮询,基于响应时间等
*
* @author stonse
*
*/
public interface IRule{
/**
* 从所有服务实例中选择一个服务实例
* @param key
* @return
*/
public Server choose(Object key);
/**
* 设置负载均衡器
* @param lb
*/
public void setLoadBalancer(ILoadBalancer lb);
/**
* 获取负载均衡器
* @return
*/
public ILoadBalancer getLoadBalancer();
}
一个负载均衡器可以使用一个负载均衡规则。
负载均衡的关系图如下:
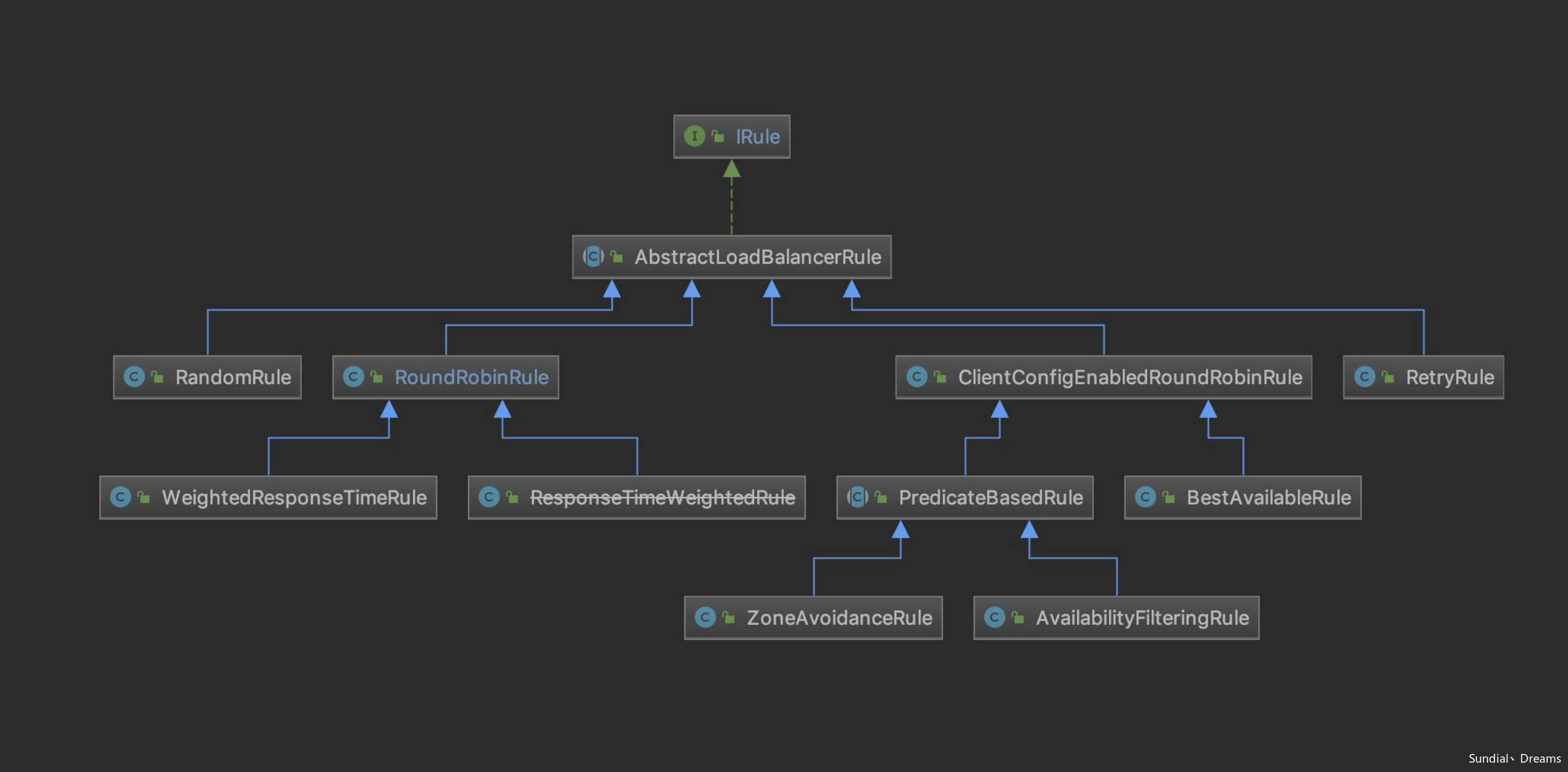
依然是一个超类,AbstractLoadBalancerRule:
/**
* 提供了一个设置和获取负载均衡器的默认实现
*/
public abstract class AbstractLoadBalancerRule implements IRule, IClientConfigAware {
private ILoadBalancer lb;
@Override
public void setLoadBalancer(ILoadBalancer lb){
this.lb = lb;
}
@Override
public ILoadBalancer getLoadBalancer(){
return lb;
}
}
仅仅是提供了一个设置和获取负载均衡器的默认实现。
ribbon为我们提供了多种负载均衡策略,我们只需看不同策略的choose()方法即可。
3.3.1 RoundRobinRule
要想讲负载均衡策略,入门策略就是Round Robin。
@Override
public Server choose(Object key) {
return choose(getLoadBalancer(), key);
}
public Server choose(ILoadBalancer lb, Object key) {
// 校验负载均衡器
if (lb == null) {
log.warn("no load balancer");
return null;
}
Server server = null;
int count = 0;
while (server == null && count++ < 10) {
// 获取可用服务实例和所有服务实例,并进行校验
List<Server> reachableServers = lb.getReachableServers();
List<Server> allServers = lb.getAllServers();
int upCount = reachableServers.size();
int serverCount = allServers.size();
if ((upCount == 0) || (serverCount == 0)) {
log.warn("No up servers available from load balancer: " + lb);
return null;
}
int nextServerIndex = incrementAndGetModulo(serverCount);
server = allServers.get(nextServerIndex);
if (server == null) {
Thread.yield();
continue;
}
if (server.isAlive() && (server.isReadyToServe())) {
return (server);
}
server = null;
}
// 10次都没有从负载均衡器中找到可用的存活集群,记录错误,返回空服务实例
if (count >= 10) {
log.warn("No available alive servers after 10 tries from load balancer: "
+ lb);
}
return server;
}
- 实现方法会获取负载均衡器后,调用核心实现方法。
- 校验负载均衡器。
- 获取负载均衡器中存储的可用服务实例列表和所有服务实例列表,并进行校验。
- 使用AtomicInteger存储集群轮询索引,通过getAndIncrement()方式取余,获取对应的下一个服务实例游标。
- 如果集群可用,直接返回;不可用的话,会重试十次,如果找了十次都不可用,返回空服务实例。
3.3.2 BestAvailableRule
BestAvailableRule是基于ClientConfigEnabledRoundRobinRule的负载均衡规则,而ClientConfigEnabledRoundRobinRule:
/**
* 基本上是基于IClientConfig的RoundRobinRule二次封装
*/
public class ClientConfigEnabledRoundRobinRule extends AbstractLoadBalancerRule {
}
是基于IClientConfig的Round Robin负载均衡规则的二次封装。
我们来看下它的choose()负载均衡方法:
@Override
public Server choose(Object key) {
if (loadBalancerStats == null) {
return super.choose(key);
}
// 从负载均衡器中获取所有的服务实例
List<Server> serverList = getLoadBalancer().getAllServers();
// 最小并发连接数是Integer的上限
int minimalConcurrentConnections = Integer.MAX_VALUE;
long currentTime = System.currentTimeMillis();
Server chosen = null;
// 遍历该负载均衡器上所有的服务实例
for (Server server: serverList) {
// 从负载均衡器状态中获取当前服务实例的状态
ServerStats serverStats = loadBalancerStats.getSingleServerStat(server);
// 判断服务势力是否处于不可用状态
if (!serverStats.isCircuitBreakerTripped(currentTime)) {
int concurrentConnections = serverStats.getActiveRequestsCount(currentTime);
// 取一个拥有最小连接数的服务实例,下一次以此连接数为标准
if (concurrentConnections < minimalConcurrentConnections) {
minimalConcurrentConnections = concurrentConnections;
chosen = server;
}
}
}
// 如果没有选到机器,就使用Round Robin负载均衡规则选择服务实例
if (chosen == null) {
return super.choose(key);
} else {
return chosen;
}
}
- 首先我们会从负载均衡器中取出所有服务实例。
- 我们会设置一个最小并发连接数的阈值,用于接下来比较最小连接数,阈值默认是Integer.MAX_VALUE。
- 遍历该负载均衡器上所有的服务实例。
- 从负载均衡器状态中获取当前服务实例的状态。
- 判断服务是否处于断路状态,接下来会讲断路周期的计算方式。
- 获取一个拥有最小连接数的实例,下一次以此连接数座位标准。
- 如果没有选出服务实例,那么就会采用Round Robin负载均衡规则选出一个服务实例。
最优选举策略总结下来就是,从可用服务列表中选取一个请求数较少的服务,已达到平衡的效果。
断路器周期计算:
- 获取失败连接数和失败请求阈值。
- 如果失败连接数小于失败请求阈值,那么断路周期为0,即不需要断路。
- 如果失败连接数超出阈值,计算断路秒数。
而断路时间节点的计算公式是:
上次失败连接的时间节点+断路周期时间
如果断路时间结束节点大于当前时间,那么当前服务实例处于不可用的状态。
ResponseTimeWeightedRule
ResponseTimeWeightedRule是基于服务实例响应时间,计算出一个权重比值,从而进行负载均衡规则路由的。
首先我们看下计算权重的全过程,ResponseTimeWeightedRule#maintainWeight():
/**
* 存储权重
*/
public void maintainWeights() {
ILoadBalancer lb = getLoadBalancer();
if (lb == null) {
return;
}
// 存在并发情况,使用CAS操作
if (!serverWeightAssignmentInProgress.compareAndSet(false, true)) {
return;
}
try {
logger.info("Weight adjusting job started");
// 获取ribbon核心组件
AbstractLoadBalancer nlb = (AbstractLoadBalancer) lb;
LoadBalancerStats stats = nlb.getLoadBalancerStats();
// 需要取每个服务实例的响应时间,如果没有负载均衡器状态,那么没有必要进行下去了
if (stats == null) {
return;
}
double totalResponseTime = 0;
for (Server server : nlb.getAllServers()) {
// 遍历每个节点,加和平均响应时间
ServerStats ss = stats.getSingleServerStat(server);
totalResponseTime += ss.getResponseTimeAvg();
}
// 权重计算公式是:集群的响应时间-总共响应时间,数字越小,权重越清
// 集群响应时间是遍历中的加和
Double weightSoFar = 0.0;
// 一次将权重叠加放入到列表中
List<Double> finalWeights = new ArrayList<Double>();
for (Server server : nlb.getAllServers()) {
ServerStats ss = stats.getSingleServerStat(server);
double weight = totalResponseTime - ss.getResponseTimeAvg();
weightSoFar += weight;
finalWeights.add(weightSoFar);
}
// 设置权重值
setWeights(finalWeights);
} catch (Exception e) {
logger.error("Error calculating server weights", e);
} finally {
// 权重设置开关关闭
serverWeightAssignmentInProgress.set(false);
}
}
- 存在并发进行计算权重的情况,我们需要进行同步同步操作。
- 获取ribbon的核心组件:负载均衡器和负载均衡器状态。
- 校验负载均衡器的状态,因为我们需要从中获取服务实例的平均响应时间。
- 遍历每个服务实例,取平均响应时间,并求和。
- 权重的计算公式是:权重 = 集群总平均响应时间 – 单服务实例的平均响应时间,集群响应时间就是上面对服务实例的平均响应时间求和而来。
- 将权重叠加放入到列表中,也就是说列表是索引为2的权重值,是列表索引0到列表索引2三个值之和。
- 设置权重值,为接下来的服务实例选取做准备。
- 最后释放同步资源。
相当于你的权重越大,所占面积越多,被选取的概率就越大。
接下来我们就看看响应时间权重负载均衡规则的核心实现,choose():
public Server choose(ILoadBalancer lb, Object key) {
if (lb == null) {
return null;
}
Server server = null;
while (server == null) {
// 因为是并发的,所以在找到合适的服务实例后,当前线程就可以退出寻找了
List<Double> currentWeights = accumulatedWeights;
if (Thread.interrupted()) {
return null;
}
List<Server> allList = lb.getAllServers();
int serverCount = allList.size();
if (serverCount == 0) {
return null;
}
int serverIndex = 0;
// 由于刚才计算权重时是叠加的,所以列表中最后一个值是前面所有值+它本身的值
double maxTotalWeight = currentWeights.size() == 0 ? 0 : currentWeights.get(currentWeights.size() - 1);
// 如果所有服务实例均没有命中,直接使用RoundRobin规则
if (maxTotalWeight < 0.001d) {
server = super.choose(getLoadBalancer(), key);
} else {
// 设定一个0到maxTotalWeight之间的一个随机值
double randomWeight = random.nextDouble() * maxTotalWeight;
int n = 0;
// 取一个值
for (Double d : currentWeights) {
if (d >= randomWeight) {
serverIndex = n;
break;
} else {
n++;
}
}
server = allList.get(serverIndex);
}
// 判断服务实例是否存在
if (server == null) {
Thread.yield();
continue;
}
// 判断服务实例是否存活
if (server.isAlive()) {
return (server);
}
server = null;
}
return server;
}
- 由于存在并发情况,所以如果线程被打断,直接退出服务实例选择。
- 由于权重列表存储的值是按步叠加的,所以我们取列表中最后一个值,就包含了所有服务实例的权重。
- 如果总体权重是0,代表还没有服务实例开始接货,所以直接使用RoundRobin策略。
- 如果总体权重大于0,它会选择一个0到1的百分比值,算出一个随机的权重值。
- 利用这个随机的权重值,我们通过遍历权重列表可以得这个服务实例的索引。
- 就取这个索引值的服务实例。
- 服务实例存活判断。
3.3.4 总结
我只举出三个有典型特点的负载均衡路由规则,它还有:
- WeightedResponseTimeRule,和ResponseTimeWeigthedRule没什么不同,只不过是进行了重写。
- RandomRule,随机负载均衡规则,随机选取一个服务实例。
- AvailabilityFilteringRule,可用性过滤负载均衡规则,它会过滤掉多次访问失败,并发连接数超过设定阈值的服务实例,并在剩余的集群中使用RoundRobin的choose()方法。
- ZoneAvoidanceRule,分区回避规则,通过排除最大连接数超出阈值的分区和存在服务实例需要断路的服务实例,在从中随机选择分区,并使用RoundRobin选取服务实例。
- AvaiabilityFilteringRule,可用性过滤负载均衡规则,它会在可以对服务实例断路的前提下,计算服务实例的断路周期,或者是排除掉活跃请求数大于设定阈值的的服务实例。
- PredicateBaseRule,过滤规则基础负载均衡规则,它会在经过断言筛选后的服务实例中,使用RoundRobinRule选取出一个服务实例。
- RetryRule,重试负载均衡规则,可以看作是RoundRobinRule的扩展,在RoundRobinRule选择出来的服务实例不存在,或者未存活,并且时间还允许的情况下,一直重试使用RoundRobinRule进行选取服务实例。
4 Ribbon实现
我们使用Ribbon来对Zuul进行一次负载均衡规则进行一次实战。
首先我们自定义一个负载均衡规则,需要继承AbstractLoadBalancerRule超类:
/**
* 自定义指定IP规则
*/
public class IPRule extends AbstractLoadBalancerRule {
@Override
public Server choose(Object key) {
ILoadBalancer loadBalancer = getLoadBalancer();
List<Server> serverList = loadBalancer.getAllServers();
for (Server server : serverList) {
if (server.getPort() == 10001) {
return server;
}
}
return null;
}
@Override
public void initWithNiwsConfig(IClientConfig clientConfig) {
}
}
自定义负载均衡规则强制将请求打到端口号是10001的本机地址上。
接着我们需要对我们的规则进行配置:
origin-one.ribbon.NFLoadBalancerRuleClassName=com.netflix.zuul.sample.sunshine.IPRule
将指定的负载均衡规则从默认的RoundRobin变为IPRule。
然后我们可以进行实验,会发现所有的请求均打到了端口为10001的服务实例上。
5 总结
- ribbon是一个封装的很好的client端负载均衡器。
- 支持archaius动态配置。
- 但是负载均衡规则实现的略显粗糙,相信他们内部应该不会使用这么粗糙的负载均衡算法。
- 外部扩展起来非常容易。

