 随遇而安
随遇而安Redis为了节约内存,从而设计了Ziplist。
它是一种经过特殊编码的双向链表,和Intset一样,是为了提高存储效率而设计的。
结构
Ziplist是一系列特殊编码的连续内存块组成的顺序链表,可以包含N个节点,每个节点可以分别存储字节数组或者是整数值。
Redis并没有给出Ziplist的具体结构,而是给出了一系列参数,这些参数进行组合,成为了一个Ziplist,下面是Redis官方给出的Ziplist的结构:
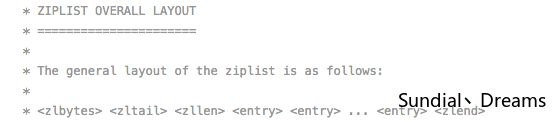
Redis定义了如下参数,组成了图中Ziplist结构的各个部分,具体代码如下:
// 获取zl的zlbytes
#define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl)))
// 获取zl起始地址到结尾之前的偏移量
#define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t))))
// 获取zl的zllen
#define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2)))
// 获取header的大小
#define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t))
// 获取end的大小
#define ZIPLIST_END_SIZE (sizeof(uint8_t))
// 获取zlbyte+zltail+zllen
#define ZIPLIST_ENTRY_HEAD(zl) ((zl)+ZIPLIST_HEADER_SIZE)
// 获取zltail
#define ZIPLIST_ENTRY_TAIL(zl) ((zl)+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl)))
// 获取结尾
#define ZIPLIST_ENTRY_END(zl) ((zl)+intrev32ifbe(ZIPLIST_BYTES(zl))-1)
所有属性均通过zl的偏移量进行获取。
创建Ziplist
当新创建一个Ziplist的时候,是不包含任何节点的,具体实现代码如下:
unsigned char *ziplistNew(void) {
unsigned int bytes = ZIPLIST_HEADER_SIZE+1;
unsigned char *zl = zmalloc(bytes);
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes);
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
ZIPLIST_LENGTH(zl) = 0;
zl[bytes-1] = ZIP_END;
return zl;
}
具体解释如下:
- 根据前面宏定义部分计算,ZIPLIST_HEADER_SIZE的位数为32 * 2 + 16 = 80,也就是10字节,再加上1字节的结尾字节数,那么bytes的值为11。
- 申请一块11字节的内存。
- 将ZIPLIST_BYTES(zl)成员初始化为11。
- 由于新创建的Ziplist是空的,所以Ziplist的起始位置到结尾位置的之前的距离是10字节大小,也就是ZIPLIST_HEADER_SIZE的大小。
- 节点数量为0。
- 将表尾成员设置成默认的255。
看起来好像依然是懵逼的,那我们形象化展示一下吧:

Ziplist节点结构
前面说了Ziplist的必备属性,接下来我们就要说一说Ziplist的节点结构了。
Redis为Ziplist的节点专门设计了一套数据结构,具体实现代码如下,**ziplist.c#
typedef struct zlentry {
unsigned int prevrawlensize; // 前置节点编码所需要的字节数
unsigned int prevrawlen; // 前置节点的长度
unsigned int lensize; // 当前节点编码所需要的字节数
unsigned int len; // 当前节点的长度
unsigned int headersize; // prevrawlensize + lensize
unsigned char encoding; // 当前节点的编码格式
unsigned char *p; // 指向当前节点数据的指针
} zlentry;
大概是Redis感觉自己设计的确实有点抽象,无注释很难理解,所以ziplist.c中充斥着大量的注释。
但是这段结构体之前还有一段注释,大意是告知大家:
哈哈,我们只是用zlentry获取ziplist的数据,实际中,我们并不在Ziplist编码这一坨,我们这么做就是为了使用起
来比较方便。
。。。
那用什么存储在Ziplist里呢?
在一堆注释中,我们终于找到了蛛丝马迹:
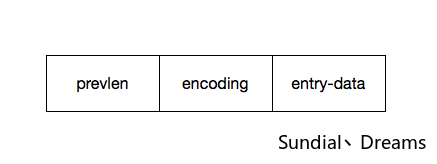
- prevlen属性用于存储前置节点的长度,prevlen的长度可以是1字节或者5字节。
- 如果前置节点的长度小于254字节,那么prevlen属性的长度就为1字节。
- 如果前置节点的长度大于255字节,那么prevlen属性的长度就为5字节,其中第一字节存储0xFE,之后四个字节用于存储前置节点的长度。
- encoding类型存储了entry-data的数据类型和长度。
- 字节数组
| 编码 | 编码长度 | content保存的值 |
|---|---|---|
| 00pppppp | 1byte | 长度小于63bytes的字节数组 |
| 01pppppp|qqqqqqqq | 2bytes | 长度小于16383bytes的字节数组 |
| 10000000|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt | 5bytes | 长度小于2^32 – 1的字节数组 |
实际实现代码如下:
#define ZIP_DECODE_LENGTH(ptr, encoding, lensize, len) do { \
ZIP_ENTRY_ENCODING((ptr), (encoding)); \
if ((encoding) < ZIP_STR_MASK) {// 字节编码格式 \
if ((encoding) == ZIP_STR_06B) { \
(lensize) = 1; \
(len) = (ptr)[0] & 0x3f;//将当前字节长度保存到len中 \
} else if ((encoding) == ZIP_STR_14B) { \
(lensize) = 2; \
(len) = (((ptr)[0] & 0x3f) << 8) | (ptr)[1]; \
} else if ((encoding) == ZIP_STR_32B) { \
(lensize) = 5; \
(len) = ((ptr)[1] << 24) | \
((ptr)[2] << 16) | \
((ptr)[3] << 8) | \
((ptr)[4]); \
} else { \
panic("Invalid string encoding 0x%02X", (encoding)); \
} \
} else {// 整数编码格式 \
(lensize) = 1; \
(len) = zipIntSize(encoding); \
} \
} while(0)
- 整数
| 编码 | 编码长度 | content保存的值 |
|---|---|---|
| 11000000 | 1bytes | int16_t类型的整数 |
| 11010000 | 1bytes | int32_t类型的整数 |
| 11100000 | 1bytes | int64_t类型的整数 |
| 11110000 | 1bytes | 有符号3byte整数 |
| 11111110 | 1bytes | 有符号1byte整数 |
| 1111xxxx | 1byte | 这个encoding没有对应的属性,因为0000~1111存储了4位立即数,直接存储即可 |
| 11111111 | 1byte | 结尾的特殊编码形式 |
实际实现代码如下:
unsigned int zipIntSize(unsigned char encoding) {
switch(encoding) {
case ZIP_INT_8B: return 1;
case ZIP_INT_16B: return 2;
case ZIP_INT_24B: return 3;
case ZIP_INT_32B: return 4;
case ZIP_INT_64B: return 8;
}
if (encoding >= ZIP_INT_IMM_MIN && encoding <= ZIP_INT_IMM_MAX)
return 0; /* 4 bit immediate */
panic("Invalid integer encoding 0x%02X", encoding);
return 0;
}
// 以encoding编码方式,将value写到p中
static void zipSaveInteger(unsigned char *p, int64_t value, unsigned char encoding) {
int16_t i16;
int32_t i32;
int64_t i64;
// 根据encoding的编码格式不同,将value写到p中
if (encoding == ZIP_INT_8B) {
((int8_t*)p)[0] = (int8_t)value;
} else if (encoding == ZIP_INT_16B) {
i16 = value;
memcpy(p,&i16,sizeof(i16));
memrev16ifbe(p);
} else if (encoding == ZIP_INT_24B) {
i32 = value<<8;
memrev32ifbe(&i32);
memcpy(p,((uint8_t*)&i32)+1,sizeof(i32)-sizeof(uint8_t));
} else if (encoding == ZIP_INT_32B) {
i32 = value;
memcpy(p,&i32,sizeof(i32));
memrev32ifbe(p);
} else if (encoding == ZIP_INT_64B) {
i64 = value;
memcpy(p,&i64,sizeof(i64));
memrev64ifbe(p);
} else if (encoding >= ZIP_INT_IMM_MIN && encoding <= ZIP_INT_IMM_MAX) {
// 无需记录在p中
} else {
assert(NULL);
}
}
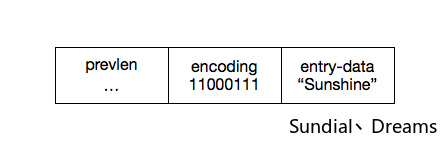
content存储了encoding属性制衡的实际数据。比如说有一个我们需要存储Sunshine,那么存储结构为:
连锁更新
在ZipEntry结构中,我们已经提到过,prevlen会随着前置节点长度的变化而变化,这相当于铁索连环,如果数据足够给力,很可能会发生连锁更新,具体实现代码如下,ziplist.c#__ziplistCascadeUpdate():
unsigned char *__ziplistCascadeUpdate(unsigned char *zl, unsigned char *p) {
size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), rawlen, rawlensize;
size_t offset, noffset, extra;
unsigned char *np;
zlentry cur, next;
// 校验是否到达Ziplist的末尾
while (p[0] != ZIP_END) {
// 获取当前数据的节点指针
zipEntry(p, &cur);
// 计算当前节点的总长度
rawlen = cur.headersize + cur.len;
// 计算当前节点编码所需要的字节数
rawlensize = zipStorePrevEntryLength(NULL,rawlen);
// 如果下一个节点是末尾节点,退出循环
if (p[rawlen] == ZIP_END) break;
// 获取下一个节点指针
zipEntry(p+rawlen, &next);
// 如果下一个节点记录的前置节点长度和当前记录的节点长度没有发生变化,退出循环
if (next.prevrawlen == rawlen) break;
// 如果下一个节点编码后的字节数无法存储当前节点编码后的字节数,需要进行扩容
if (next.prevrawlensize < rawlensize) {
// 记录偏移量
offset = p-zl;
// 需要扩展的字节数
extra = rawlensize-next.prevrawlensize;
// 扩展
zl = ziplistResize(zl,curlen+extra);
// 还原p的位置
p = zl+offset;
// 下一个节点指针的位置
np = p+rawlen;
// 下一个节点的偏移量
noffset = np-zl;
// 由于位置变化了,所以表头到表尾的距离也需要更新一下
if ((zl+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))) != np) {
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+extra);
}
// 移动next节点到新地址
memmove(np+rawlensize,
np+next.prevrawlensize,
curlen-noffset-next.prevrawlensize-1);
// 用当前节点的长度,重新计算下一个节点的前置节点字节数,并更新
zipStorePrevEntryLength(np,rawlen);
// 将p指针移动到下一个节点
p += rawlen;
// 更新Ziplist的总字节数
curlen += extra;
} else {
if (next.prevrawlensize > rawlensize) {
// 如果空间足够大,直接用5字节编码之前的1字节
zipStorePrevEntryLengthLarge(p+rawlen,rawlen);
} else {
// 如果空间刚刚好,那就更新下长度吧
zipStorePrevEntryLength(p+rawlen,rawlen);
}
// 由于下一个节点中断了连锁反应,所以退出循环
break;
}
}
return zl;
}
接下来我们形象化展示一下这个过程。
- 首先,我们有一个Ziplist。
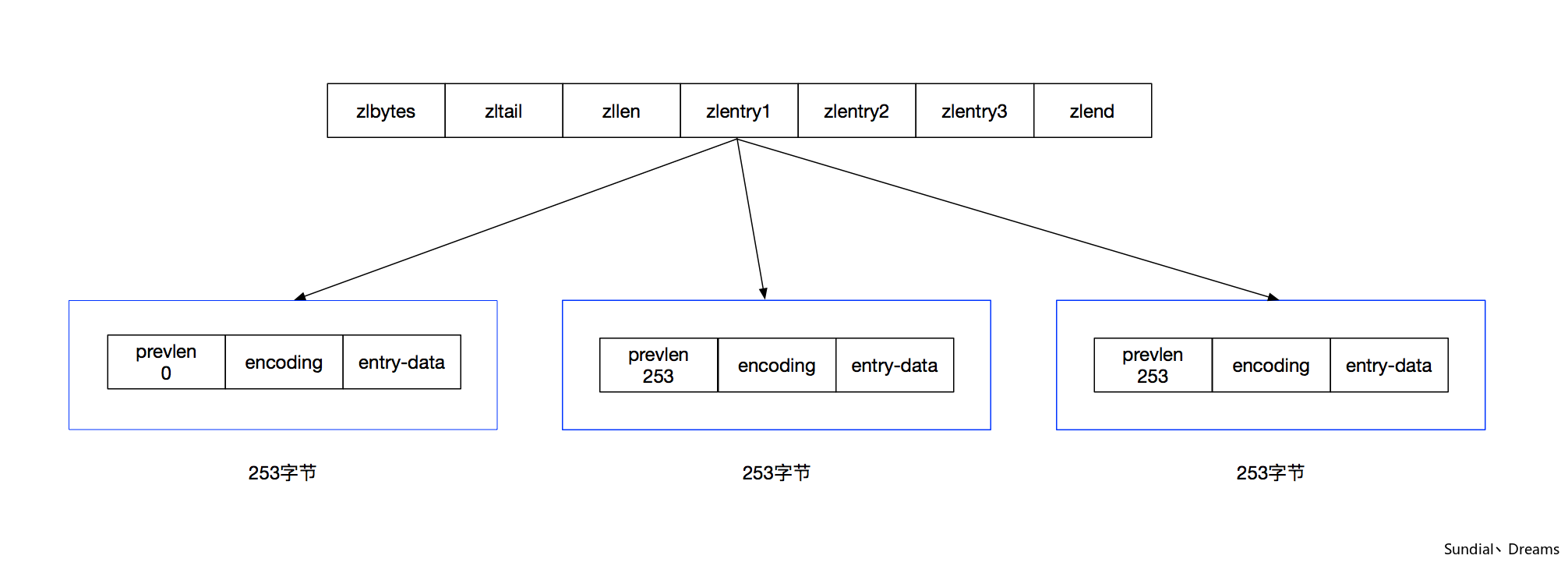
- 接着,我们向队首插入了一个ZipEntry。

- Ziplist发生了连锁更新。
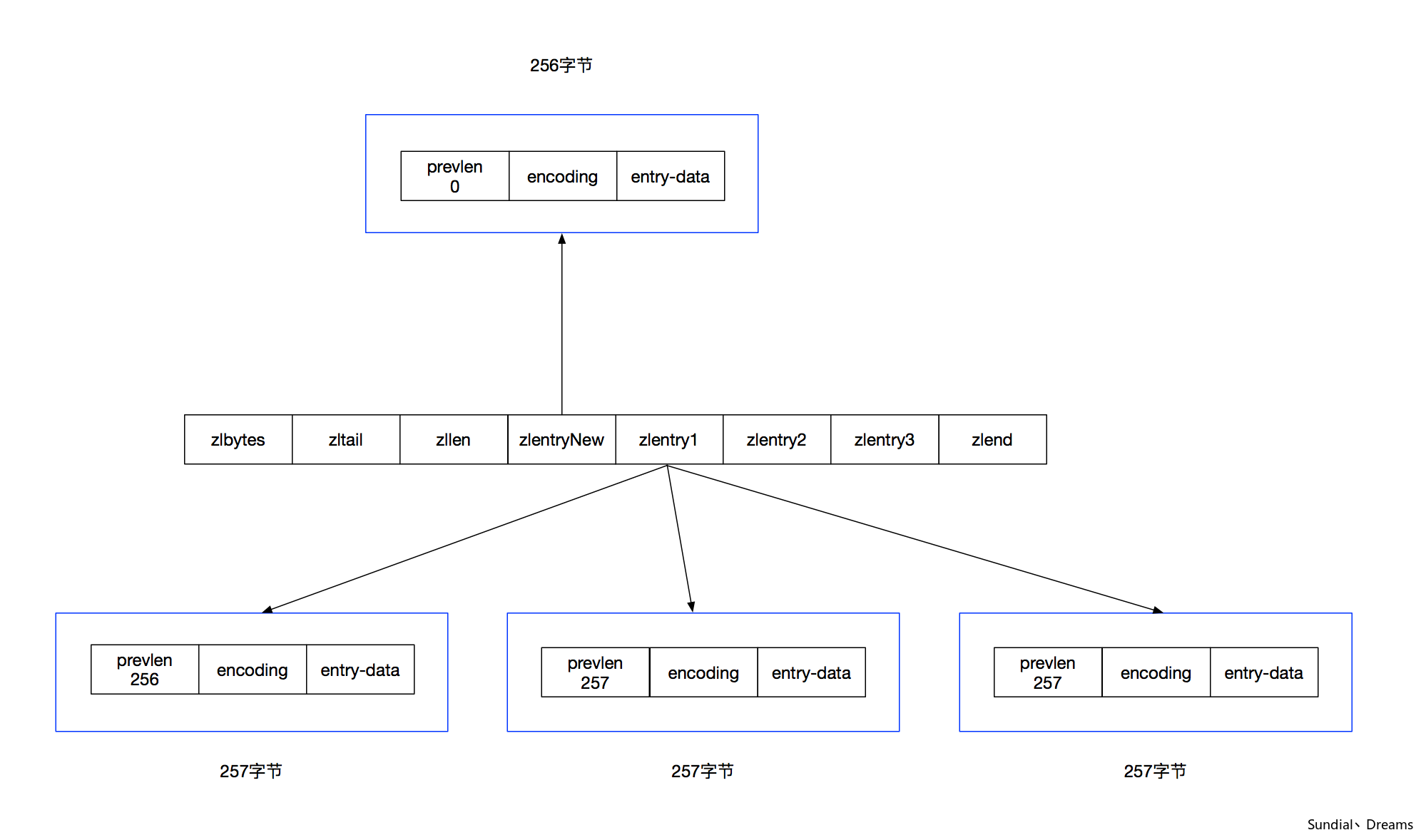
- 连锁更新在最坏的情况下需要对Ziplist执行N次空间重分配操作,而每次空间重分配的最坏时间复杂度是O(N),所以连锁更新的最坏时间复杂度是O(N^2)。
- 虽然连锁更新的时间复杂度较高,但是出现最坏连锁更新的情况比较少,因为:
- Ziplist中要恰好有多个连续的,长度介于250字节~253字节之间的节点,连锁更新才可能发生。
- Ziplist如果只对几个节点进行了连锁更新,是不会对性能造成太大影响的。
所以我们在使用Ziplist,不用过度关心连锁更新是否会影响性能。

